

AI Opportunity Map
AI is everywhere in publishing conversations — but not every opportunity carries the same business value, and not every capability is mature enough to be a priority (and there is a lot of hype and nonsense). Executives and boards want to understand what AI means for the future and how these emerging technologies might create transformative value. Staff want clarity on what’s practical today — where AI can solve today’s problems and deliver measurable benefits. Both share a desire to understand where AI tools might really be applied to their organization, and where to focus.
That’s why we created the AI Opportunity Map — a structured way for organizations to see the landscape, identify and prioritize the right opportunities, and take the next steps strategically.
The AI Opportunity Map is a decision tool that helps identify where AI investments can deliver business value. It ensures AI investments are strategic, practical, and aligned with business goals, organizational readiness, and real-world maturity.
Outliers
The Howard Hughes Medical Institute (HHMI) announced its new “Immediate Access to Research” policy this month, joining the Gates Foundation in de-emphasizing formal publication in research journals in favor of posting preprints describing funded work.
The new HHMI policy goes into effect January 1, 2026, and requires funded authors to post a CC BY (Creative Commons, with attribution) licensed preprint of research articles prior to (or upon) submission to a journal. This is referred to as the “Initial Preprint.” The author must then post an additional version (the “Revised Preprint”) when/if peer review feedback, new results, or further analysis warrant substantial revisions to the initial preprint. For internal evaluation processes, “the most recent preprint version will serve as the official version of the significant article — not any subsequent journal publication.”
While HHMI officially no longer requires publication of articles, it will still cover costs for publications — but only if the paper is published in a fully open access (OA) journal. (HHMI will not cover the cost of OA publication in hybrid journals.)
The policy aligns with the 2019 proposal for “Plan U,” which is meant to provide OA through preprints as a way to eliminate both the costs and the inequities created by the author-pays APC (article processing charge) publication model. It is hard to fathom how publication fees would pose a concern for HHMI, the second largest philanthropic organization in the US, with a $22.6 billion endowment. Nonetheless, the policy is framed as a response to researcher concerns about the high costs of publication, specifically calling out $13,000 APCs (which we assume is directed at Nature). Given how few papers are published in Nature relative to all the other journals in the world with APCs, this is akin to saying the cost of cars is high and then pointing to the price of a Rolls-Royce. OK, sure, a Rolls is expensive, but that doesn’t tell you much of anything about the price that 99.99% of people who buy cars pay for those cars. Focusing on an outlier data point to make your case is exactly the kind of argument that would get flagged in journal peer review.
While HHMI may not require journal publication, HHMI-funded researchers will no doubt continue to publish in peer-reviewed journals. HHMI funding is not attached to the graduate students and postdocs doing most of the actual research and writing those papers — rather, the grants are awarded to the labs’ principal investigators (PIs). For the PI, the preprint may suffice as it satisfies their funder, but for the student/postdoc, formal publication is still necessary if they hope to land a job or secure funding of their own. Even without the pressure from students and postdocs, PIs may also wish to publish for their own career advancement, to build a track record to apply for grants from other funders in the future, or for the sake of collaborators (among other reasons).
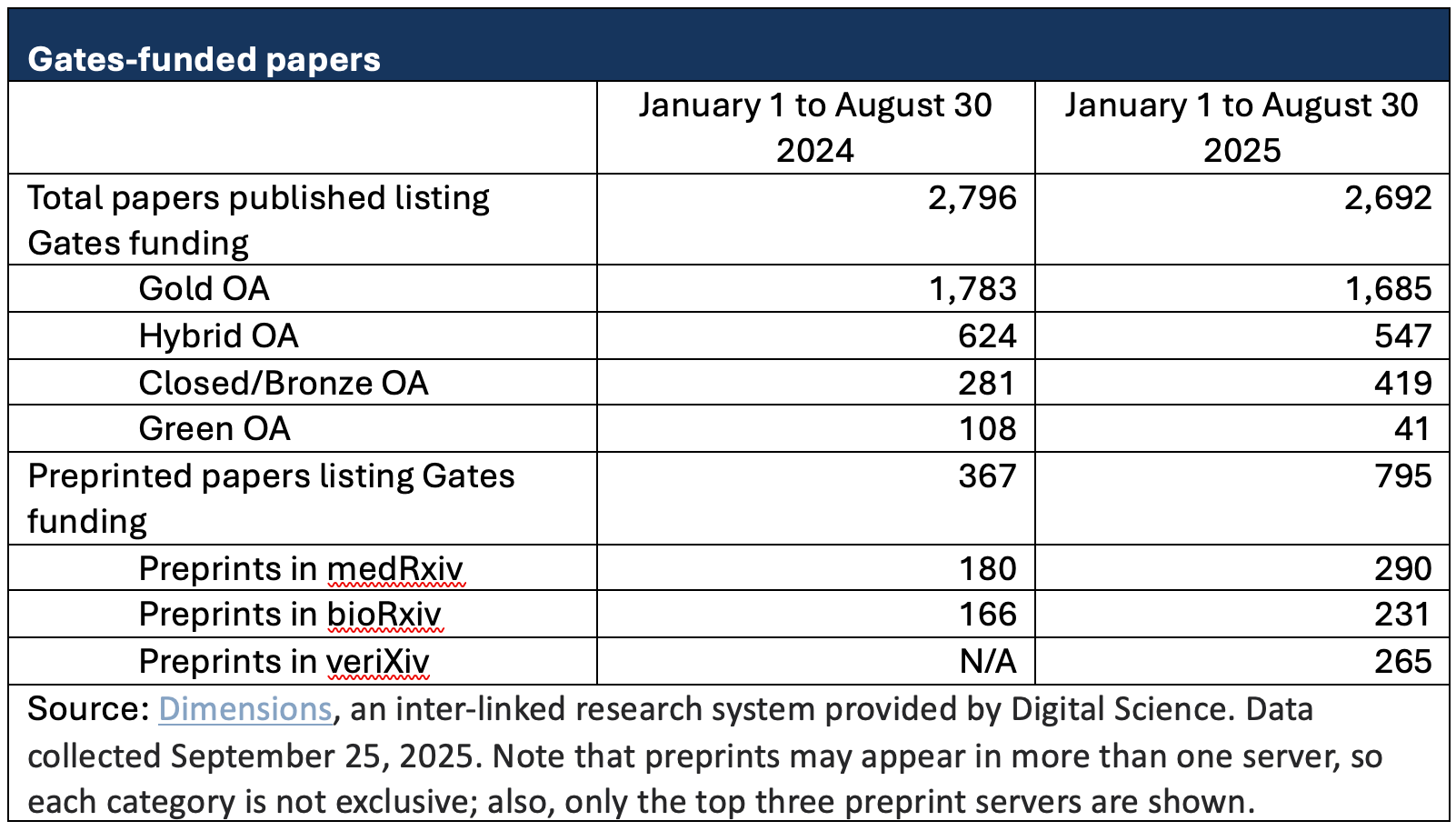
This continued interest in journal publication, even without funder requirement to do so, is seen in the publishing behavior of Gates-funded authors. The table below shows the publication status of articles before and after the new Gates policy went into effect (at the beginning of 2025)
Data for the past two years show a similar number of papers published that list Gates funding, which suggests that the policy of only requiring preprints has not effectively changed publication behavior nor slowed down the flow of articles to journals. Roughly similar numbers appear in both years for publication in fully OA and hybrid journals, with an increase seen for publication in subscription journals (listed above as “Closed/Bronze OA”) in 2025.
The Gates policy has, however, had an impact on preprinting, with more than twice as many papers preprinted in 2025 as in 2024 at this point. To note, even if we ignore the possibility of papers being preprinted on more than one server, this still represents less than 30% compliance for papers listing Gates funding, so there is still a long way to go before preprinting becomes the norm, even where required, for these authors. Even though Gates-funded authors are encouraged to post on veriXiv, those who are preprinting seem to prefer medRxiv, with bioRxiv also popular, suggesting that these preprinting authors are going to the servers with higher visibility compared to Gates’ newly launched veriXiv server.
A cynical observer might suggest HHMI’s policy retains the benefits (e.g., amplification and validation) of having its research in peer-reviewed publications (including hybrid journals), while shifting much of the cost associated with publication to universities.
Researchers at universities that sign transformative agreements with publishers will be able to publish in hybrid journals covered by those agreements at no charge (to the researcher). In this sense, the new HHMI policy further privileges researchers at large and well-funded research universities that sign transformative agreements. And it benefits the largest publishers, with the scale to negotiate such agreements.
That said, it is perhaps worth some perspective. HHMI-funded research resulted in approximately 1,800 papers in 2024 — around 0.03% of the total literature. The Gates Foundation funded more research, resulting in 4,000 papers — roughly 0.07% of the total literature. These are tiny funding agencies in the scheme of things. Gates funded fewer papers last year than Bristol Meyers Squibb. Even taken together, Gates and HHMI funded fewer papers in 2024 than Pfizer.
Will either policy move the needle as far as the larger market? It seems doubtful, at least at this point. Plan S, which impacted more than 37 times as many papers as HHMI and Gates combined, shifted publisher strategies toward OA. But even so, those effects were largely limited to Europe and most notably spurred the spread of transformative agreements, which are effectively workarounds to Plan S. Funders such as HHMI and Gates receive an outsized amount of attention from the publishing industry, but they are outliers, due to both their vast wealth and their miniscule publication output. Time will tell whether the policies of these outliers translate beyond their own small communities.
AI + Marketing
The new SAS report, Marketers and AI: Navigating New Depths, shows just how firmly generative AI has taken hold in the world of marketing. Eighty-five percent of marketers are now using the technology, and adopters report benefits — from efficiency and cost savings to better insights, stronger targeting, and more personalized customer experiences. In this research, generative AI is defined broadly, being used not only for generating text, images, or code, but also in chatbots, analytics, personalization, and customer journeys.
On the horizon looms so-called agentic AI. Where generative AI responds to prompts, agentic AI operates more autonomously — executing tasks with minimal human input once configured. According to the report, 21% of marketers are already testing agentic AI in live environments, and nearly three-quarters plan to adopt it within two years.
The report also highlights several factors that determine success — these mirror the practices we have been advising the organizations we work with to adopt:
- Strong data foundations to support AI use at scale. Without clean, connected, and well-governed data, organizations struggle to move beyond AI pilots.
- Clear processes and training plans so staff can use AI tools effectively. This includes structured approaches to messaging — for example, building dynamic message libraries, such as our Capsule Messaging Collection™, which ensure consistency, adaptability, and readiness for AI-driven content generation.
- Robust governance with space for human oversight to ensure trust and accountability. Governance is about more than compliance; it’s about giving teams confidence that AI is being used responsibly, with safeguards such as explainability, ethical guidelines, and human-in-the-loop practices.
- A clear roadmap for how AI capabilities are integrated into the marketing department — spanning skills, tools, and processes. This is where organizations need to assess their MarTech platforms realistically, since we see a widening divide between tools with real AI functionality and those without.
CC = Continued Confusion
Uncertainty still reigns over the legality of using copyrighted content to train AI systems such as large language models (LLMs), a market that Ian Mulvany estimates to be worth at least $1 to $2 billion for journal articles. Earlier this month, Anthropic reached a $1.5 billion settlement in its court case over illegally downloading and storing books from LibGen, the database that powers Sci-Hub. While some see this as a win for authors, others see the settlement as a cynical business ploy to limit competition and prevent startups from being able to afford to enter the market. The judge in the case has denied preliminary approval of the settlement, so its final fate is yet to be determined.
Regardless of the outcome, long-running confusions continue about Creative Commons (CC) licenses and their potential role in limiting LLM training. This last month, Punctum Books offered a passionate call to arms for OA publishers to take collective action against AI scraping of scholarly content released under OA licenses. But as University of Illinois Urbana-Champaign professor and librarian Lisa Janicke Hinchliffe points out, CC licenses (including non-commercial NC or share-alike SA clauses) apply to conditions of republishing those materials, not the access, reading, or use of those materials. This is a fundamental concept necessary to understand CC licenses, the difference between “use” of the content (e.g., downloading it, reading it, and applying the ideas it contains) and “reuse” of the content (specifically republishing those exact words and images in that particular order).
LLM training is not republication, although at least one judge suggests that later outputs from those trained LLMs could be considered as such. Courts seem to be leaning toward the actual training use of content as transformative, and thus it is “fair use” and not subject to copyright restriction. And, as Hinchliffe states: “any CC license is an *expansion* on what is allowed under copyright. None of them take away what one can do with copyrighted content.”
OA publishers may be unhappy with the increased traffic their websites are seeing from AI bots, and authors may be unhappy with rapacious corporations gobbling up their work and offering no recompense, but by publishing OA, that’s what they signed up for. One of the main motivations for governments to fund research (and to issue open/public access requirements to the results of that funded research) is to drive economic growth. The fruits of research are meant to create jobs and tax revenues for the country. We often hear about poor startup companies unable to afford to subscribe to the research journals they need to build their new products, a problem OA solves.
But as so often is the case regarding OA and open research in general, everything seems like a great idea until you’re the one on the hook for paying publication costs or it’s your hard work that others can now freely exploit. If we truly believe in knowledge as a public good, then we must recognize that giant rapacious tech corporations are part of that public.
Briefly Noted
The September 15 deadline for responses to the National Institutes of Health (NIH)’s “Request for Information on Maximizing Research Funds by Limiting Allowable Publishing Costs” has passed and a variety of stakeholders have weighed in. The STM Association notes that while US spending on research has doubled in the past decade and the volume of papers published has increased by 60%, overall revenues for journal publishing have only increased 18% over that time. STM also states that the NIH’s proposed APC amounts are unrealistic, even for the sustainability of non-profit publishers that don’t need to generate surpluses, and that limiting spending will limit the communication of the research results being funded. The Association of Research Libraries (ARL) urges the NIH not to implement spending caps, which will “simply shift high costs elsewhere rather than addressing their root causes” and instead suggests emphasizing the Green OA route to compliance. The American Society for Pharmacology and Experimental Therapeutics (ASPET) argues that price caps would create a “two-tiered publishing system” where well-funded authors would continue to publish in high-quality journals and under-resourced researchers would be pushed toward low-cost or predatory publishers. PLOS suggests that a better path would be to encourage research assessment reform and to support collective funding to enable open publishing models, while maintaining quality.
A separate research project suggests that a $2,000 cap on APCs would only cover the publication fees for 6% of the papers published in 2025, and $3,000 only 21%. The group concurs with our earlier analysis in The Briefthat imposed caps would likely drive the uptake of Read and Publish deals by libraries, rendering funder caps largely moot.
In further APC news, the American Astronomical Society has introduced an OA fee structure that we haven’t seen before, basing author charges on “quanta,” which apparently include the number of words in the article as well as number of figures, tables, data, and other components of the manuscript.
The NIH has terminated its Literature Selection Technical Review Committee. This was the group that decided what gets into MEDLINE. The NIH states that this was part of an effort to “modernize operations” and “strengthen transparency,” but as of this writing, no further details are available as to how one now gets a journal reviewed for inclusion.
The US Environmental Protection Agency (EPA) has ordered some of its researchers to immediately pause the publication of research results, and that going forward all publications will need to be approved by political appointees.
In perhaps the most startling revelation from this year’s Peer Review Week, we learned that, despite all the “sky is falling” commentary around peer review, it actually works. Regarding a new study from Clear Skies, Adam Day writes, “there is a step in the peer-review process which is highly accurate. It’s slow, error-prone, and expensive, but it is spectacularly good at identifying problematic research. That step is called ‘peer review’.”
While many have suggested that the hyper-competitive nature of science funding is inefficient and bad for science, a new preprint by Kevin Gross and Carl Bergstromargues that, “competition for scarce resources — for example, publications in elite journals, prestigious prizes, and faculty jobs — motivates scientific risk-taking and may be important in counterbalancing other incentives that favor cautious, incremental science.”
Copim suggests that publishers will be facing increasing costs due to the UK’s “Online Safety Act,” which will require online platforms to provide age verification checks. And in other unintended consequences of poorly planned policy news, the EU’s Deforestation Regulation is causing chaos throughout the world of book publishing, as selling books in the UK will soon require submission of the geo-coordinates of the forest where the trees for the book’s paper were sourced, the Latin names of the species of the trees that were used, and the dates upon which the trees were cut down, into a complex, back-and-forth regulatory system. It is estimated that over 100,000 non-compliant books in UK warehouses will have to be pulped and that many publishers will simply cease selling books in the EU market, resulting in the EU “effectively banning a far broader range and number of books than the Florida book bans.”
Academia.edu (reminder, this is a private company that registered the .edu domain before such URLs were restricted to educational institutions) saw something of a backlash when it announced new terms of servicerequiring users to grant the company license, permission, and consent to use “your name, voice, signature, photograph, likeness, city, institutional affiliations, citations, mentions, publications, and areas of interest” for advertising and sales purposes. While a company spokesperson has stated that the new terms have been revised to exclude that language, as of this writing, the site’s Terms of Use page still includes these requirements.
Wiley’s Q1 2026 earnings call was upbeat. On the call, James Flynn (Executive Vice-President and General Manager of Research & Learning) reported “submissions up 25% year-on-year and output growth 13%.” When asked about the outlook for 2026 subscription renewals, Flynn indicated muted optimism: “The outlook is fine.” Wiley talked a lot about AI licensing on their call. They were keen to point to $29 million in AI licensing in the first quarter with some of that revenue being due to licensing on behalf of other publishers — which is an interesting development.
Bucknell University Press has announced plans to cease operations at the end of the 2025–2026 fiscal year.
Tough times in the book distribution business, as Baker & Taylor, the country’s largest library wholesaler, saw its acquisition by ReaderLink fall through at the last minute.
For those without openly licensed content, a new licensing standard, RSL (Really Simple Licensing) offers the potential for charging AI companies to crawl and use that content. Although the RSL itself won’t stop AI companies that already ignore instructions in a website’s robots.txt file, when paired with a pay-per-crawl system that blocks bots such as those offered by Cloudflare or potentially Fastly, the RSL might make for an effective collective licensing system.
In another indicator of the ongoing flood of AI slop being generated, the journal Expert Opinion on Drug Safetyhas had to stop accepting submissions based on a public database of drug safety signals that has become a favorite target for AI-generated paper mill manuscripts.
Faisal Hoque at Fast Company suggests we are not simply in an AI bubble — we are in three of them. There is the asset bubble, which is basically the inflated stock prices of AI companies. There is the infrastructure bubble, which is reflected in the nation-state levels of capex spending by tech giants on data centers ($1 trillion so far in 2025). And, finally, the hype bubble. Which, Hoque notes, is not to say there isn’t real, lasting innovation happening — just that, in the short term, it may not live up to the hype. He argues that “companies with systematic approaches to extracting value from the technology will thrive.” We agree with this assessment. AI has most certainly entered a bubble phase (or three of them) but that doesn’t mean there are not real opportunities for thoughtful and prudent organizations. When the correction comes, pricing on AI technologies will be on sale, and organizations that have done the groundwork implementing relevant systems and processes, and building expertise, may find themselves ahead of competitors.
NISO, the National Information Standards Organization, has released a draft set of Recommended Practice for Open Access Business Processes, meant to offer “a shared glossary to eliminate confusion over terminology, clear metadata specifications to ensure information flows smoothly between systems, and guidance on reporting, financial tracking, and agreement management.” The draft is open for comments through October 17.
The continuing dilution of the scholarly literature to include increasing amounts of unvetted and questionable materials is problematic in many ways, but particularly how false information gets picked up and spread by the popular media. A new study suggests that science journalists have a “limited awareness” of predatory journals, but like the victims of most scams, they “largely believe predatory journals are a problem for their peers, or a problem in theory, but not one they would ever fall for themselves.” Meanwhile, a Science Advances paper suggests that detecting problematic journals may be a job better suited for AI.
Two studies released on simultaneous days offer a glimpse into how devastating the US government’s active and proposed cuts to science funding are likely to be. Both studies looked at past NIH grants, with one group training an AI to find grants that would likely have been flagged by the current administration for cancellation, and the other looking at the lowest-scoring 40% of NIH grants awarded with an assumption that the proposed 40% budget reduction would have eliminated those projects. The number of drugs and treatments that would have been lost is stunning. More bad news can be found in The New York Times article on the results of the US government essentially “Shutting Down the War on Cancer.”
And if you think your job is difficult, try being a librarian tasked with tracking down non-existent books hallucinated by AI.
***
In the end, not all openness is virtuous; not all resistance to openness is obstructionist. —Amy Brand (Director and Publisher, The MIT Press)